attend 리팩토링을 해야 하는데 자꾸 미루네요. 저번주 주말은 캠핑을 다녀왔습니다. 너무 힘들어요.
여튼 이번주는 월요일~화요일 공부한 스프링 게이트웨이와 유레카에 대해 간단히 소개 드리겠습니다.
gateway 는 말그대로 게이트웨이입니다. 사용자가 요청하면 요청을 받고 url 을 분석해서 적절한 서버로 전달해주는 역할을 합니다. eureka 는 마이크로 서비스 명단을 관리 해주는 역할을 합니다. 서비스 각각을 제어하지 않고 누가 살았는지 명단만 잘 관리해줍니다.
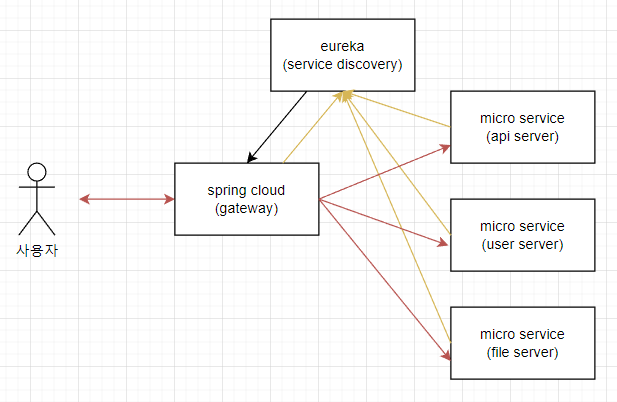
그림을 보면 이해가 쉬우실 겁니다.
순서대로 한번 보겠습니다. 일단 eureka 가 떠 있다고 가정하겠습니다.
(노란색 화살표) 스프링 클라우드가 뜨면서 eureka 에 등록을 합니다.
(노란색 화살표) 마이크로서비스도 뜨면서 eureka 에 다 등록이 됩니다.
현재 살아있는 서버는 api, user, file, gateway 가 되겠죠. eureka 가 정기적으로 heartbeat 를 수신 받으면서 살아있는지 체크를 합니다. 만약 heartbeat 가 안오면 죽었다고 판단을 하는 것 입니다.
(빨간색 화살표) 사용자가 /api/blah/blah 로 요청을 보냅니다. spring cloud 는 url 을 읽고 api 서버로 보내야 함을 압니다.
(검은색 화살표) 그리고 게이트웨이에서 살아있는 api 서버 목록을 받습니다. 살아있는 서버 중 하나로 유저의 요청을 보냅니다.
현재 조사가 안된게 “게이트웨이에서 살아있는 api 서버 목록을 받습니다” 이 부분입니다. 목록을 받는건지 살아있는 서버 중 한곳을 리턴하는건지 더 조사해야 합니다.
이런 구조의 장점은 micro service 의 scale-out이 간편하다는 것 입니다.
더 알아 보아야 할것은 로드 밸런싱 종류입니다. 기본적으로 설정되는 로드 밸런싱 방법은 round robin 입니다. 서버 사양이 다를 경우 한 서버에 부하가 심해질 수 있으므로 다른 방법을 찾아야 할 것 같습니다.
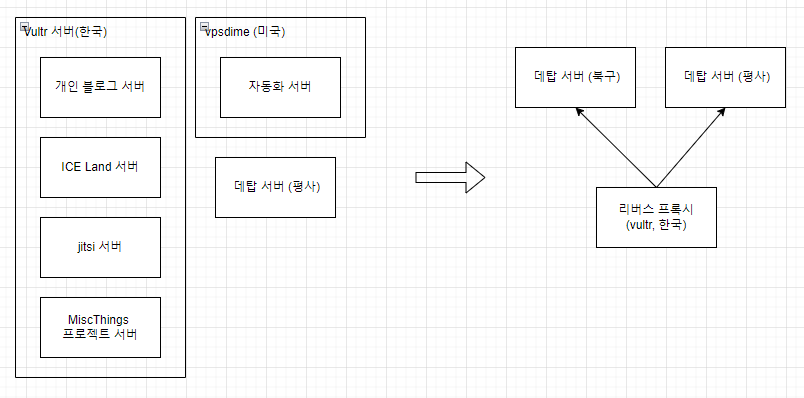
최종 목표는 이겁니다. 가상 서버가 사양에 비해 금액이 적지 않다고 판단하였고 더 높은 사양을 원하기에 물리 서버를 두대 둬야한다고 생각 했습니다. 클라우드에 비해 물리서버가 죽을 확률은 높아서 프록시 서버는 클라우드에 한대 뒀습니다. 리버스 프록시에서 로드 밸런싱과 서버 health check 를 담당할 예정입니다.
우선은 북구에 놓을 서버가 없기에 Linode 60달러짜리 서버를 한대 빌렸습니다. 지금은 데탑 서버(평사)와 리노드(일본) 두대가 있습니다.
이제 자동 배포를 구축할 겁니다. 기존에는 리눅스 서비스를 만들어두고 관리하는 방식으로 했는데 코드를 변경할 때 마다 재시작 명령어를 입력해줘야 해서 배포하기가 매우 귀찮았습니다. 이걸 젠킨스를 통해 자동화 할 계획입니다.
게다가 서비스마다 각각 다른 부분이 있어 신경써야 할 부분이 많습니다. 이걸 도커로 만들어두면 서비스를 올릴 때 같은 명령으로 전부 처리할 수 있고 어느 환경에서나 동일하게 동작하기 때문에 배포할 때 뇌를 덜 사용해도 됩니다. 그리고 docker-compose를 사용할 겁니다. docker run 뒤에 오는 수많은 옵션을 관리하는 것도 상당히 귀찮은 일 입니다. docker-compose 는 이런 옵션들을 파일로 만들어뒀다고 생각하시면 됩니다. 옵션을 미리 파일로 저장해 두고 docker-compose up -d 만 입력하면 서비스가 올라갑니다.
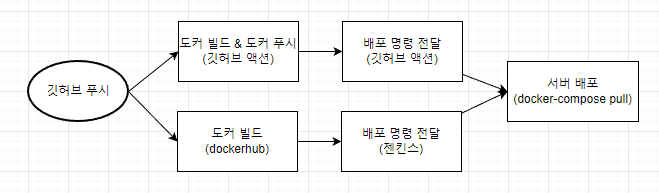
빌드 촉발은 깃허브 푸시로 진행할 겁니다. 지금 생각하고 있는 배포 방식은 두가지 입니다.
도커 허브를 잘 활용하기 위해 깃허브에서 푸시가 들어오면 도커 빌드 → 도커 푸시 과정을 거치는것은 똑같습니다. 다만 깃허브 액션으로 빌드와 푸시를 할것인지, 도커 허브를 통해 빌드를 할것인지는 선택해야 합니다.
깃허브 액션으로 하면 다음과 같은 특징이 있습니다
+ 빌드, 배포를 한 곳에서 관리 가능함.
- CI Minute 을 보고 비용 신경써야 함.
△ 배포 명령 전달시 젠킨스를 사용해도 됨
도커 허브와 젠킨스를 사용하면 다음과 같은 특징이 있습니다
+ 젠킨스 사용으로 자동화 자유도가 넓어짐
- 과정이 좀 복잡함. (깃허브 푸시 → 도커 허브 → 젠킨스 순)
△ 어짜피 도커 허브 프로를 샀는데 활용하자는 마인드
지금은 dockerhub 를 통해 빌드하고 있습니다. 이제 젠킨스 세팅을 알아보겠습니다.
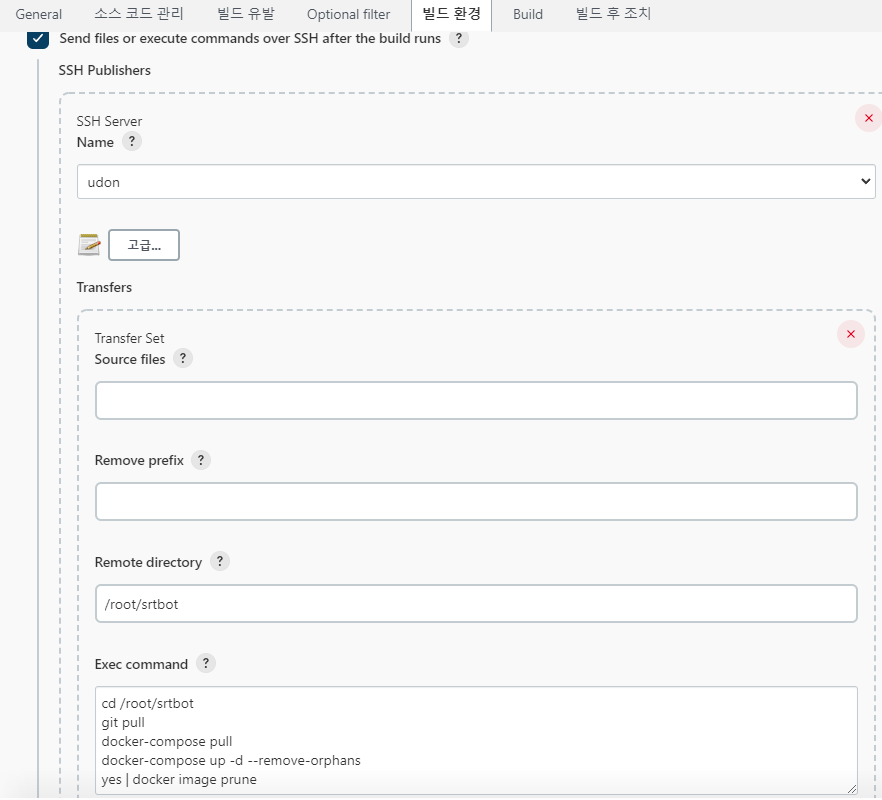
처음 젠킨스를 설치하고 할 일은 다음과 같습니다.
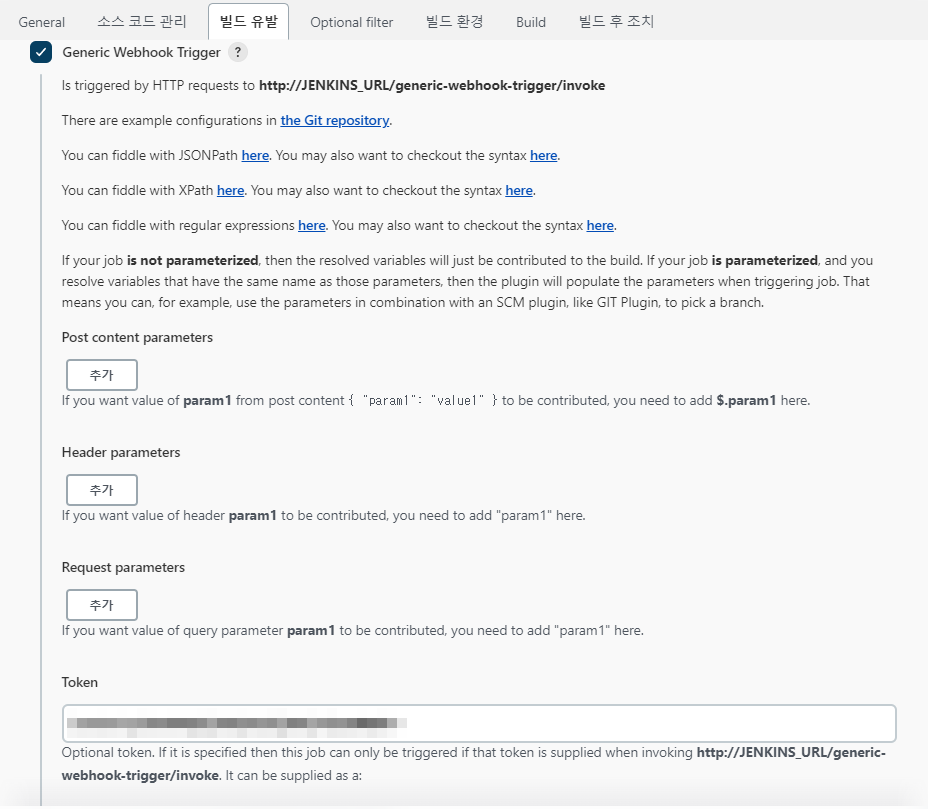
웹훅 플러그인 설치, 배포(over ssh 로 검색) 플러그인 설치
대상 서버에서 ssh-keygen 을 하고 이 키를 깃허브에 등록합니다. (docker-compose 파일을 받기 위함)
배포 플러그인(Publish over SSH) 에서 ssh 서버 추가 (관리 → 시스템 설정 에 있음)
대상 서버에서 레포지토리 받기(또는 docker-compose 파일만 있어도 됨)
빌드 유발은 웹훅 입니다. 젠킨스에서 웹훅 플러그인을 깔고 토큰을 설정해 주면 됩니다.
빌드 환경 설정은 다음과 같습니다. 말이 빌드 환경일 뿐이지 사실은 서버에 접속해서 도커 재시작 해주는 명령이 전부 입니다.
cd /root/srtbot
git pull
docker-compose pull
docker-compose up -d --remove-orphans
yes | docker image prune
위 명령어를 젠킨스가 웹훅이 들어오면 실행해 줍니다.
이로써 자동 빌드 환경이 구성되었습니다. git commit 과 push 를 하게 되면 dockerhub → jenkins → 서버에서 docker-pull 과정을 거쳐서 서비스가 최신 상태로 올라오게 됩니다.
다음은 attend 프로젝트의 도커화와 cockroach 데이터베이스 연결, sqlite3 에서 cockroach 데이터베이스로 데이터 이동을 할 것 같습니다.
DU Things 에 속하는 Attend 서비스는 출석 QR 코드를 미리 저장해서 원클릭으로 출석하는 서비스입니다.
이 서비스는 2019년 처음 개발되었습니다. 비공개로 아는 사람끼리만 쓰다가 MiscThings 동아리를 개설하면서 장애학생을 위한 서비스로 2021년 11월에 공개 했습니다.
기능은 단순합니다. 그냥 출석 QR 코드를 미리 찍어 두면 다음부터는 사이트에 접속해서 출석 버튼을 누르기만 하면 됩니다. (물론 기존과 같이 DU Wifi 에 연결되어야 함.)
출석 QR 코드를 그냥 브라우저에 저장해도 됐지만, QR 코드를 이용해 출석 링크를 생성하는 과정에서 복호화가 필요합니다. 아무래도 복호화 키를 공개하는 것은 무리가 있다고 판단했습니다. 또한 기기간 연동도 될 수 있게 하려면 사용자 관리까지 들어가야 할 것 같아서 백엔드 서버를 두기로 했습니다. 그래서 백엔드 서버의 역할은 아래와 같습니다.
회원 관리 (출석 QR 데이터 저장)
QR 복호화
이벤트 관리
처음 구상했던건 QR 복호화와 회원 관리 밖에 없었습니다. QR 복호화는 데이터베이스 필요 없이 값을 해독해서 응답을 주면 되었고 회원 관리는 따로 데이터베이스가 필요했습니다. 일단 사용자가 많지 않을거라고 생각해서 sqlite 로 간단하게 개발했습니다. 하지만 공개 이후 많은 사용자들에게 배포해보자 라는 욕심이 생겼고 적극적인 홍보를 통해 지금은 약 1100명이 사용하고 있습니다.
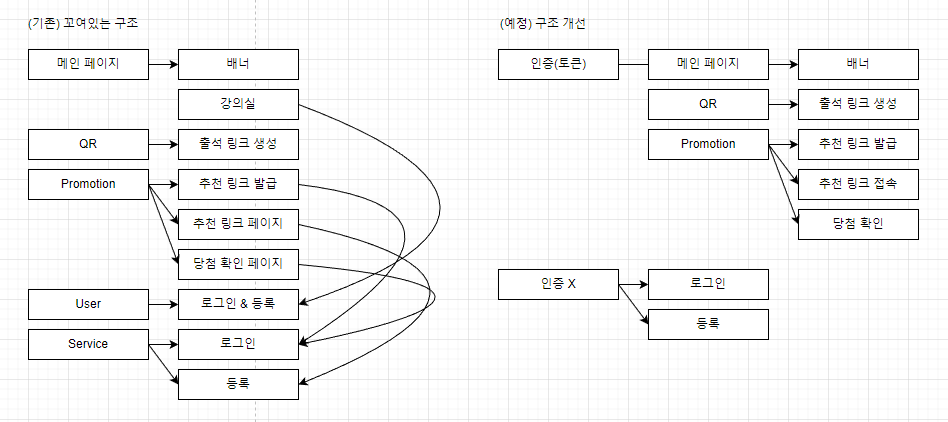
리팩토링이 필요한 이유는 다음과 같습니다.
데이터베이스 관리.
서버 관리
두가지 걱정거리에 대해서 알아보겠습니다. 서비스를 운영하기 위해서 1100명의 인증 정보와 강의실 정보를 저장해야 합니다. 현재 데이터베이스 구조는 sqlite 를 사용하여 KV 저장소와 비슷하게 구성되어 있습니다. Key 는 ID 로 Value 는 암호와 강의실 정보로 이루어진 JSON 을 담고 있습니다. 지금 json 이 잘못 저장되면 복구 할 수 있는 방법이 딱히 없기도 하고 실수로 지워버리면 돌이킬 수 없기 때문에 안정성이 높은 클라우드로 이전하려 합니다.
두번째는 서버 관리입니다. 현재는 vultr 에 가상서버 1대만 구성되어 있습니다. 업데이트를 할 때나 인스턴스 장애가 일어난경우 백엔드와 프론트엔드 모두 중단되는 구조입니다. 고가용성을 위해 홈서버를 포함하여 운영해볼 계획입니다.
그럼 다시, 데이터베이스는 뭘 고르고 서버 구조는 어떻게 구성해야 할 지 고민해야 합니다.
서버 언어는 Java 로 단계적으로 전환할 겁니다. Spring, JPA 연습 겸 선택했습니다.
데이터베이스는 cockroach database 를 사용할겁니다. 고가용성에 맞게 구성된 데이터베이스기도 하고 클라우드 서비스를 제공해줍니다.
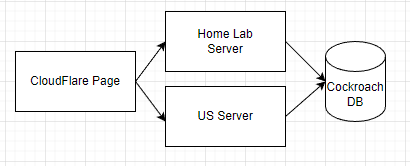
서버 구조는 아래와 같이 구성했습니다.
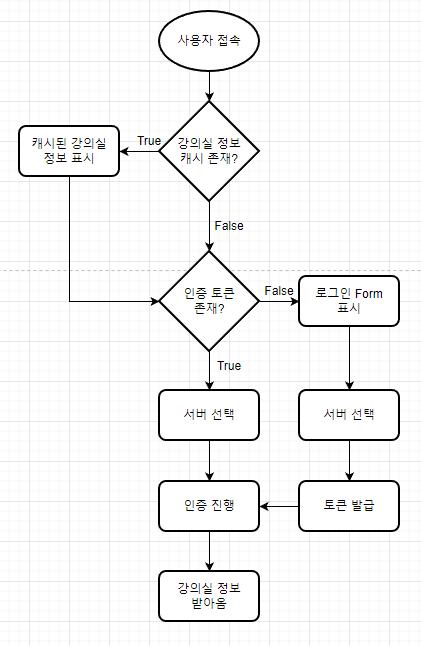
cockroach db 도 cloud 상에 있고 정적 파일 또한 cloudflare page 라는 cloud 상에 있습니다. 정적 페이지 상에서 서버 목록을 읽고 연결을 테스트하고 가장 빠른 서버를 선택하게 할 것입니다. 물론 이 과정이 느리다는것은 잘 알고 있습니다. 아마 클라이언트에서 아래와 같은 단계를 거칠 것입니다.
서버를 여러대 두고 고를 수 있게 한다면 세션 관리를 각 서버마다 동기화 해줘야 합니다. 이 과정은 매우 어렵고 귀찮기 때문에 jwt(Json Web Token) 를 사용할 겁니다. 서버간 비밀키만 공유되면 어디에서든 토큰 검증을 할 수 있기 때문입니다.
위와 같이 서버 선택이 가능하도록 구현한다면 하나의 서버가 죽었을 때 클라이언트에서 나머지 접속이 가능할 것입니다. 보통은 HA Proxy 같은 소프트웨어를 사용하지만 관리할 서버를 줄이기 위해 클라이언트에서 서버를 선택하게 개선할 것입니다.
백엔드 서버 구조도 개선해야 합니다. 현재는 로그인 코드에 의존되어 있는게 많은데 인증 절차를 토큰으로 대신함으로써 미들웨어에서 전부 처리할 예정입니다.
Attend 특성상 방학기간에는 사용자가 없는 서비스입니다. 방학기간 내에 리팩토링을 마치고 과정까지 업로드 하겠습니다 😘
DU Attend 는 QR코드를 미리 휴대폰에 저장해두고 앉은자리에서 편리하게 출석체크 해 주는 서비스입니다.
시대의 흐름에 따라 개인정보의 중요성이 커져가면서 본인의 데이터가 안전한지 궁금해하는 사용자들이 많습니다. 서비스를 만드는 입장에서는 귀찮아할 일이 아니라 데이터 관리를 어떻게 하는지 적극적으로 알려드려야 할 부분 같습니다. 이러한 문화가 많이 퍼졌으면 좋겠습니다.
수집하는 식별정보
DU Attend 서비스에서는 사용자의 정보를 최소한으로 수집합니다. 순수 무료 목적으로 만들어졌기 때문에 다음과 같은 정보만 수집합니다.
아이디 -> 학번으로 유도
암호
DU Attend 서비스에서 다른 서비스들과 다른 점은 아이디를 학번이랑 동일하게 해야 합니다. 사실 학번을 사용하지 않고 무작위 8자리 숫자를 사용해도 됩니다. 학번을 사용하는 이유는 출석 시스템에서 학번을 사용하기 때문입니다. 무작위 8자리로 가입하거나 다른 사람의 학번으로 가입하게 되면 출석 기능이 제대로 동작하지 않을 것 입니다.
출석 QR과 관련된 정보는 나중에 다른 글로 정리하겠습니다.
암호는 tigers(종합정보시스템) 암호가 아닙니다. DU Attend 에서 개별적으로 사용하는 암호입니다. 현재 암호 정책은 최소 4자리 최대 36자리 로 제한하고 있습니다. 숫자 4자리로 해도 되지만 좀 더 강력한 암호를 사용하시면 좋겠습니다. 암호의 중요성은 잘 아실 거라 생각합니다.
암호 저장방법
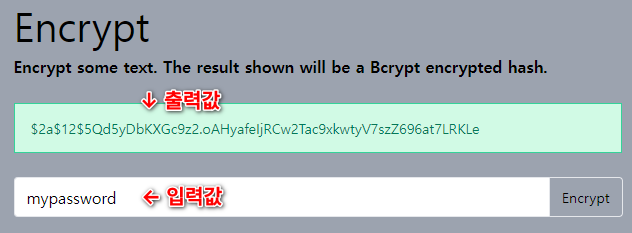
암호 정보는 해시 함수를 사용하여 저장합니다. 해시 함수란 위키백과에 잘 정리되어 있습니다.
해시함수(hash函數)는 하나의 주어진 출력에 대하여 이 출력으로 사상시키는 하나의 입력을 찾는 것이 계산적으로 불가능하고, 하나의 주어진 입력에 대하여 같은 출력으로 사상시키는 또 다른 입력을 찾는 것이 계산적으로 불가능하다는 두 가지 성질을 만족하면서 임의의 비트열을 고정된 길이의 비트열로 사상시키는 함수이다.
한마디로 입력값을 해시 함수에 통과시키면 무작위 문자로 보이는 결과물이 출력됩니다. 해시 함수는 출력값으로 입력값을 유추할 수 없어야 합니다.
그리고 해시 함수의 알고리즘은 널리 알려져 있습니다. 알고리즘이 공개되어 있어도 많은 곳에서 사용한다는 것은 안전하다는 뜻이기도 합니다.
DU Attend 에서 사용하는 해시 함수는 bcrypt 입니다. bcrypt 의 장점은 많은 언어에서 구현되어 있어 사용하기 편리하고(개발 속도가 빠르고) 아직 알려진 문제가 없다는 점 입니다. 그리고 해시를 생성할 때 마다 다른 출력값이 나온다는 점 입니다.