- 컴포넌트 스캔
1-1 컴포넌트 스캔과 의존관계 자동 주입 시작하기
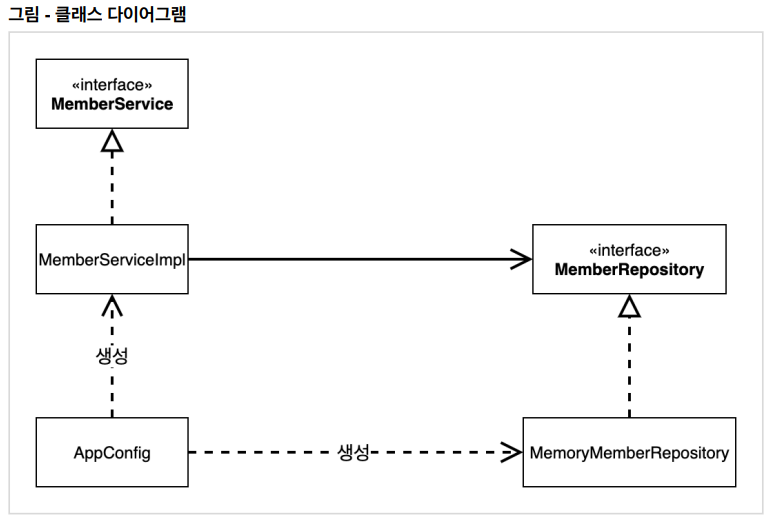
– 기존의 @Bean 방식을 @Component 방식으로 변경
– AppConfig에 @Configuration과 @ComponentScan 애노테이션을 설정
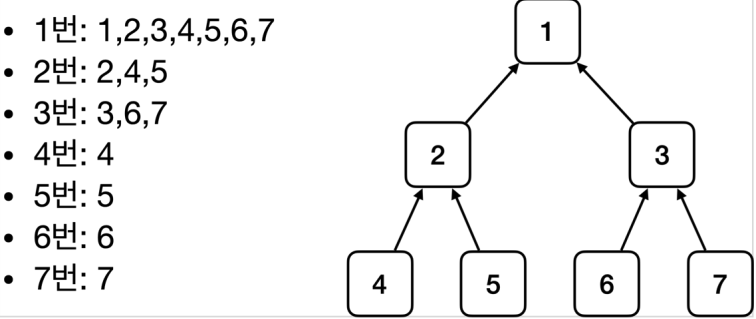
– 이 때 @ComponentScan은 @Component가 붙은 모든 클래스를 스프링 빈으로 등록
– 각 클래스가 컴포넌트 스캔의 대상이 되도록 @Component 애노테이션을 각각 붙임
– ServiceImpl등 생성자로 Repository 따위를 전달 받는 곳에 @Autowired를 통해 의존관계를 자동으로 주입 받음 (스프링 컨테이너가 자동으로 해당 스프링 빈을 찾아서 주입)
1-2 기본 스캔 대상
– 컴포넌트 스캔은 @Component 뿐만 아니라 아래 내용도 추가로 대상에 포함
— @Component : 컴포넌트 스캔에서 사용
— @Controlller : 스프링 MVC 컨트롤러에서 사용 (스프링 MVC 컨트롤러로 인식)
— @Service : 스프링 비즈니스 로직에서 사용 (스프링 데이터 접근 계층으로 인식하고, 데이터 계층의 예외를 스프링 예외로 변환)
— @Repository : 스프링 데이터 접근 계층에서 사용 (스프링 설정 정보로 인식하고, 스프링 빈이 싱글톤을 유지하도록 추가 처리)
— @Configuration : 스프링 설정 정보에서 사용
1-3 필터
– includeFilters : 컴포넌트 스캔 대상을 추가로 지정
– excludeFilters : 컴포넌트 스캔에서 제외할 대상을 지정
– FilterType 옵션
— ANNOTATION: 기본값, 애노테이션을 인식해서 동작한다.
ex) org.example.SomeAnnotation
— ASSIGNABLE_TYPE: 지정한 타입과 자식 타입을 인식해서 동작한다.
ex) org.example.SomeClass
— ASPECTJ: AspectJ 패턴 사용
ex) org.example..Service+ REGEX: 정규 표현식 ex) org.example.Default.
— CUSTOM: TypeFilter 이라는 인터페이스를 구현해서 처리
ex) org.example.MyTypeFilter
1-4 중복 등록과 충돌
– 자동빈 등록 vs 자동 빈 등록
— 컴포넌트 스캔에 의해 자동으로 스프링 빈이 등록
— 이름이 같은 경우 스프링은 오류를 발생 (ConflictingBeanDefinitionException)
– 수동 빈 등록 vs 자동 빈 등록
— 수동 빈 등록이 우선권을 가짐 ( 수동 빈이 자동 빈을 오버라이딩) - 의존관계 자동 주입
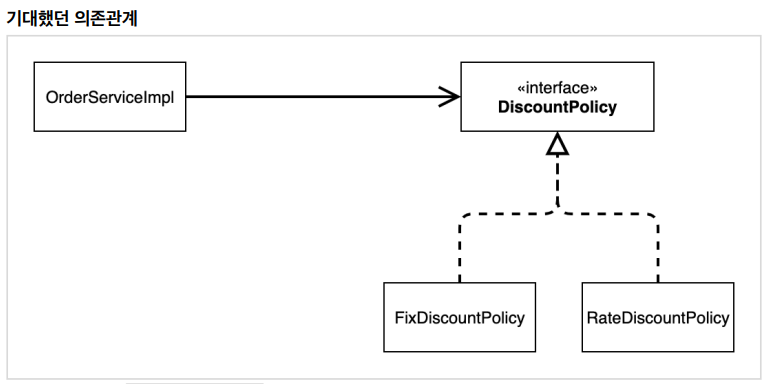
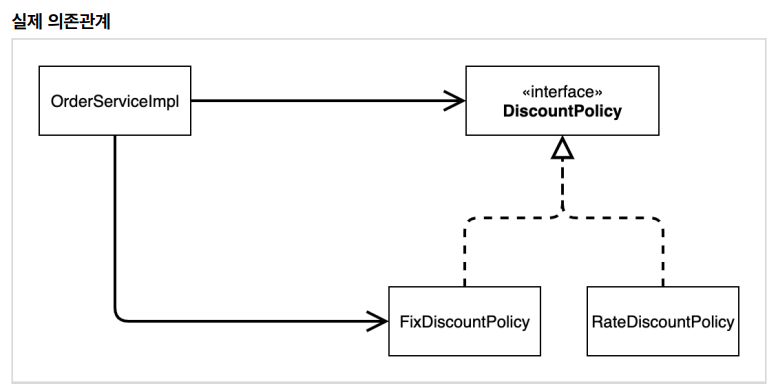
2-1 다양한 의존 과계 주입 방법
– 생성자 주입 (권장)
— 생성자 호출시점에서 딱 1 번만 호출되는 것이 보장
— 불변, 필수 의존관계에 사용
– 수정자 주입 (setter 주입)
— setter라 불리는 필드의 값을 변경하는 수정자 메서드를 통해 의존관계를 주입
— 선택, 변경 가능성이 있는 의존관계에 사용
— 자바빈 프로퍼티 규약의 수정자 메서드 방식을 사용
– 필드 주입
— 코드가 간결
— 외부에서 변경이 불가능해서 테스트 하기 힘들다는 단점
— DI 프레임워크 없이 불가
— 사용 자제
– 일반 메서드 주입
— 한번에 여러 필드를 주입 가능
— 일반적으로 사용하지 않음
2-2 옵션 처리
– 주입할 스프링 빈이 없어도 동작을 필요로 할 때가 있음
– @Autowired만 사용하면 required 옵션의 기본값이 true로 되어 있어 자동 주입 대상이 없으면 오류를 발생
– 자동 주입 대상을 옵션으로 처리하는 방법
— @Autowired(required=false) : 자동 주입할 대상이 없으면 수정자 메서드 자체가 호출 안 됨
— org.springframework.lang.@Nullable : 자동 주입할 대상이 없으면 null이 입력
— Optional<> : 자동 주입할 대상이 없으면 Optional.empty 가 입력
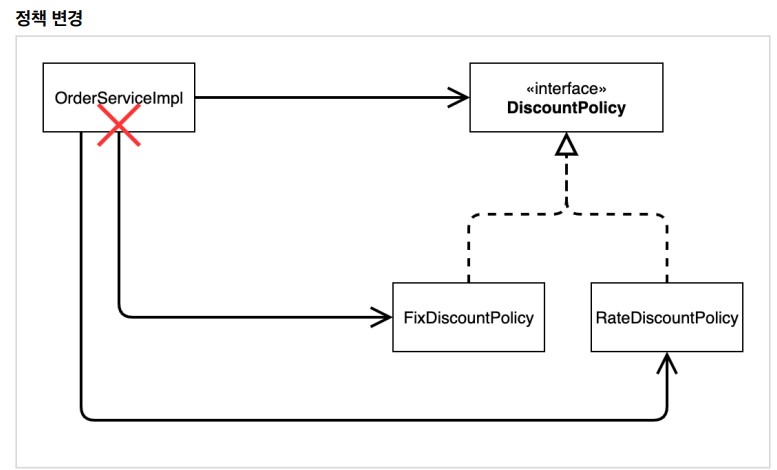
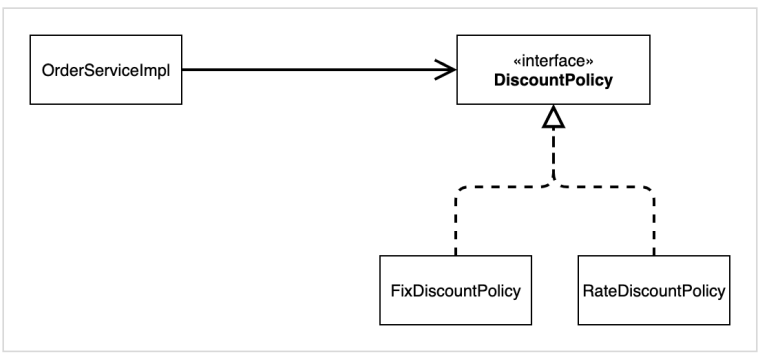
2-3 생성자 주입 선택 권장 (결론)
– 대부분의 의존관계 주입은 한번 일어나면 애플리케이션 종료시점까지 의존관계를 변경할 일이 없음
– 오히려 대부분의 의존관계는 애플리케이션 종료 전까지 변하면 안 됨 (불변)
– 수정자 주입을 사용하면, setXxx 메서드를 public으로 열어두어야 함
– 누군가 실수로 변경할 수 도 있고, 변경하면 안되는 메서드를 열어두는 것은 좋은 설계 방법이 아님
– 생성자 주입은 객체를 생성할 때 딱 1번만 호출되므로 이후에 호출되는 일이 없음, 따라서 불변하게 설계할 수 있음
– final 키워드
— 생성자 주입을 사용하면 필드에 final 키워드 사용 가능
— 생성자에 혹시라도 값이 설정되지 않는 오류를 컴파일 시점에서 막아줌
2-4 롬복 라이브러리
– @RequiredArgsConstructor : final이 붙은 필드를 모아서 생성자를 자동으로 만들어 줌 (롬복이 자바의 애노테이션 프로세서라는 기능을 이용) - 빈 생명주기 콜백
3-1 빈 생명주기 콜백 시작
데이터베이스 커넥션 풀이나, 네트워크 소켓처럼 애플리케이션 시작 시점에 필요한 연결을 미리 해두고, 애플리케이션 종료 시점에 연결을 모두 종료하는 작업을 진행하려면, 객체의 초기화와 종료 작업이 필요
– 스프링 빈의 라이프사이클 (간략화) : 객체 생성 -> 의존관계 주입
— 스프링 빈은 객체를 생성하고, 의존관계 주입이 다 끝난 다음에야 필요한 데이터를 사용할 수 있는 준비가 완료
— 따라서 초기화 작업은 의존관계 주입이 모두 완료되고 난 다음에 호출해야 함
— 스프링은 의존관계 주입이 완료되면 스프링 빈에게 콜백 메서드를 통해서 초기화 시점을 알려주는 다양한 기능을 제공
— 스프링은 스프링 컨테이너가 종료되기 직전에 소멸 콜백을 줌
— 따라서 안전하게 종료 작업 진행 가능
스프링 빈의 이벤트 라이프사이클
( 스프링 컨테이너 생성 -> 스프링 빈 생성 -> 의존관계 주입 -> 초기화 콜백 -> 사용 -> 소멸전 콜백 -> 사용 -> 소멸전 콜백 -> 스프링 종료 )
– 초기화 콜백 : 빈이 생성되고, 빈의 의존관계 주입이 완료된 후 호출
– 소멸전 콜백 : 빈이 소멸되기 직전에 호출
( 참고 : 생성자는 필수 정보(파라미터)를 받고, 메모리를 할당해서 객체를 생성하는 책임을 가진다. 반면에 초기화는 이렇게 생성된 값들을 활용해서 외부 커넥션을 연결하는등 무거운 동작을 수행한다. 따라서 생성자 안에서 무거운 초기화 작업을 함께 하는 것 보다는 객체를 생성하는 부분과 초기화 하는 부분을 명확하게 나누는 것이 유지보수 관점에서 좋다. 물론 초기화 작업이 내부 값들만 약간 변경하는 정도로 단순한 경우에는 생성자에서 한번에 다 처리하는게 더 나을 수 있다. )
– 스프링 빈 생명주기 콜백 방법
— 1. 인터페이스 InitializingBean, DisposableBean
— InitializingBean, DisposableBean를 implements하여 클래스 생성
— InitializingBean 은 afterPropertiesSet() 메서드로 초기화를 지원
— DisposableBean 은 destroy() 메서드로 소멸을 지원
— 초기화, 소멸 인터페이스 단점 : 각 인터페이스는 스프링 전용 인터페이스이므로 해당 코드가 의존 ( 메서드 이름 변경 불가, 내가 코드를 고칠 수 없는 외부 라이브러리에 적용 불가 – 거의 사용하지 않음 )
— 2. 빈 등록 초기화, 소멸 메서드 지정
— 설정 정보에 @Bean(initMethod = “init”, destroyMethod = “close”) 처럼 초기화, 소멸 메서드를
지정 가능
— 자유로운 메서드 이름 수정
— 스프링 빈이 스프링 코드에 의존하지 않음
— 코드가 아니라 설정 정보를 사용하기 떄문에 코드를 고칠 수 없는 외부 라이브러리에도 초기화, 종료 메서드를 적용할 수 있음
— 3. 애노테이션 @PostConstruct, @PreDestroy (권장)
— 최신 스프링에 가장 권장되는 방법
— 애노테이션 하나만 붙이면 되므로 매우 편리
— 스프링 종속적 기술이 아닌 JSR-250라는 자바 표준 ( 패키지 javax.annotation.PostConstruct )
— 단점 : 외부 라이브러리에 적용 불가, 외부 라이브러리를 초기화, 종료 해야 하면 @Bean의 기능을 사용
◆ 그 외 사항
포스팅 계획 – 4월 : MVC 모델링, 정처기 실기(+중간) / 5월 : 스프링부트, MVC 모델링 / 6월 : 졸업 작품(+기말) / 7월 : 스프링부트 / 8월 ~ : 알고리즘과 CS, JPA, 스프링부트를 포함한 미정
- 아직 해당 작성글에 틀린 부분이 많은 것으로 예상됩니다. 언제나 댓글 환영입니다
- 그리고 이 글은 인프런 김영한 선생님의 Spring 로드맵 과정입니다