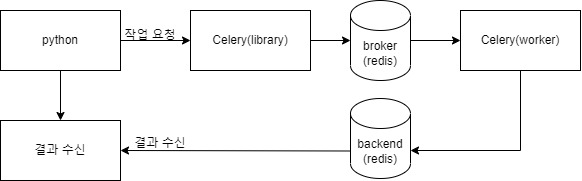
대구대 사이트에 있는 정보들을 하나로 통합하여 검색할 수 있으면 좋을 것 같아 개발하였습니다.
현재 대구대 사이트에는 아래와 같은 시설 검색이 가능합니다.
- 편의 시설 정보(매점, 복사실, 편의점)
- 학과 정보(학과 홈페이지 안내)
- 교직원 연락처 정보(내선 번호)
추가적으로 비공개 데이터도 있습니다
- 강의실 목록
이러한 데이터를 검색하려면 메뉴를 누르고 링크를 타고 접속해야 검색이 가능합니다.
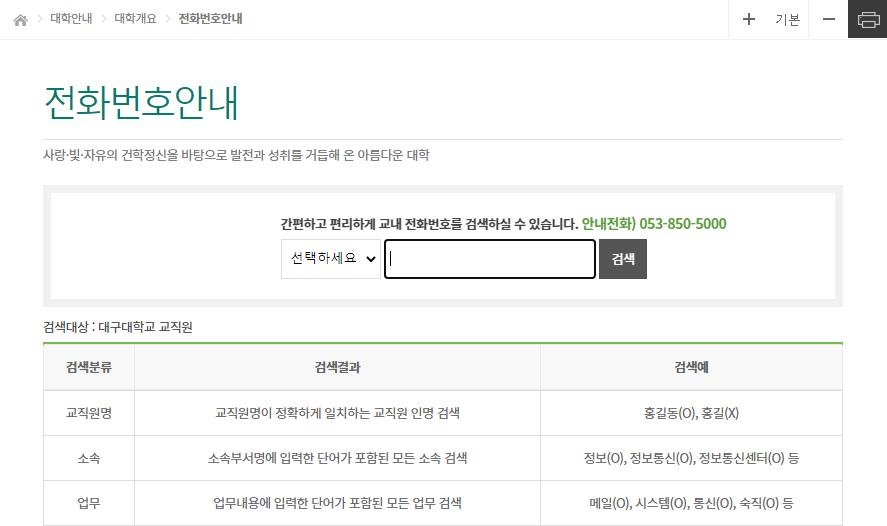
예를 들어 전화번호를 검색하려면
① 상단 메뉴에서 대학안내 → 대학개요 → 전화번호안내 링크를 통해 접속하고
② 검색 분류를 선택한 뒤
③ 전화번호를 검색 해야 합니다.
이런 파편화된 데이터를 하나의 검색 박스에서 위 나열된 것을 검색하도록 하는것이 목표입니다.
우선 현재 데이터는 전부 JSON 으로 저장되어 있습니다. 예시 JSON 은 다음과 같습니다.
# 강의실 정보
{
"id":"법행1100",
"name":"1층 공통공간",
"floor":"1층",
"type":"17558688",
"location":"법행정대학관"
}
# 시설 정보
{
"id": "중앙도서관열람관",
"sectors": "편의점",
"name": "이마트24",
"floor": "지하",
"office_phone": "",
"phone_number": "010-****-****",
"type": "10263233"
}
# 학과 정보
{
"id":"인문대학",
"name":"한국어문학부",
"url":"http://koreandu.daegu.ac.kr/",
"image_url":"http://koreandu.daegu..."
}
# 연락처 정보
{
"name_kr": "강**",
"upmu": null,
"buseo": "재활과학대학 재활건강증진학과",
"user_upmu": "교육지원조교",
"bojik_nm": " ",
"sosok": null,
"jik_id": "*****",
"user_telno": "6095",
"e_mail": "********@naver.com",
"hompy_addr": null,
}이 정보를 키워드 형태로 검색할 수 있게 가공해야 합니다.

MariaDB 같은 RDBMS에 집어넣으려면 JSON을 표 처럼 변환해줘야 합니다. 검색과 별개로 사용자에게 보여줄 정보는 필요하기 때문에 필수적인 항목만 추려 보았습니다.
이제 위 형태로 변환시키는 코드를 만듭니다. 배열로 처리 할 수 있지만 기억력도 좋지 않은데다 표를 봐 가면서 해야하기 때문에 dataclass 로 정의해보도록 하겠습니다.
from dataclasses import dataclass
from typing import Optional
@dataclass
class CsvForm:
idx: Optional[int] = None
blah_id: Optional[str] = None
name: Optional[str] = None
location: Optional[str] = None
tel_no: Optional[str] = None
mobile_no: Optional[str] = None
category: Optional[str] = None
web_address: Optional[str] = None
email_address: Optional[str] = None
tags: Optional[str] = None
def __get_data_array(self):
return [
self.idx, self.blah_id, self.name, self.location,
self.tel_no, self.mobile_no, self.category, self.web_address,
self.email_address, self.tags,
]
def __getitem__(self, item):
return self.__get_data_array()[item]
def __repr__(self):
return self.__get_data_array()
def __len__(self):
return len(self.__get_data_array())
어쨌든 CSV 로 변환해야 하기 때문에 class 형태지만 배열처럼 동작해야 합니다. __getitem__() 과 __len__() 을 구현해 줌으로써 배열 처럼 동작하게 할 수 있습니다.
(2) 에서는 sqlite3 을 사용해서 메모리에 데이터베이스를 올리고 쿼리 생성까지 만들어 보겠습니다.