Miscthings 동아리 활동을 하면서 다양한 서비스를 만들고 배포하고 있는데요.
사용자의 편의성을 증대하기 위해 기존에 진행하고 있는 서비스를 보완하고 통합 어플을 만들고자 합니다.
기존의 제작하고 있던 밥약과 다양한 정보들을 통합하여 제공하여 재학생의 만족도를 높여가는 서비스를 완성 시키도록 하겠습니다.
This is not a spaghetti, it’s jjamppong
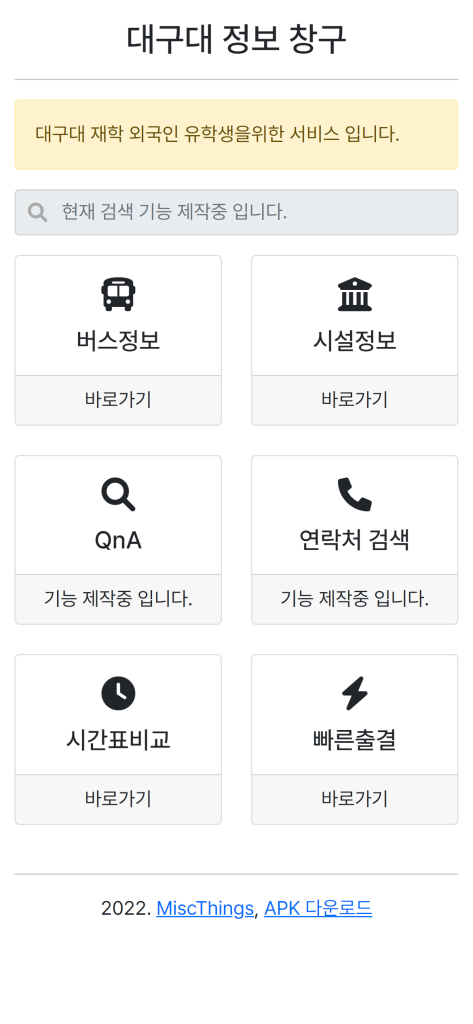
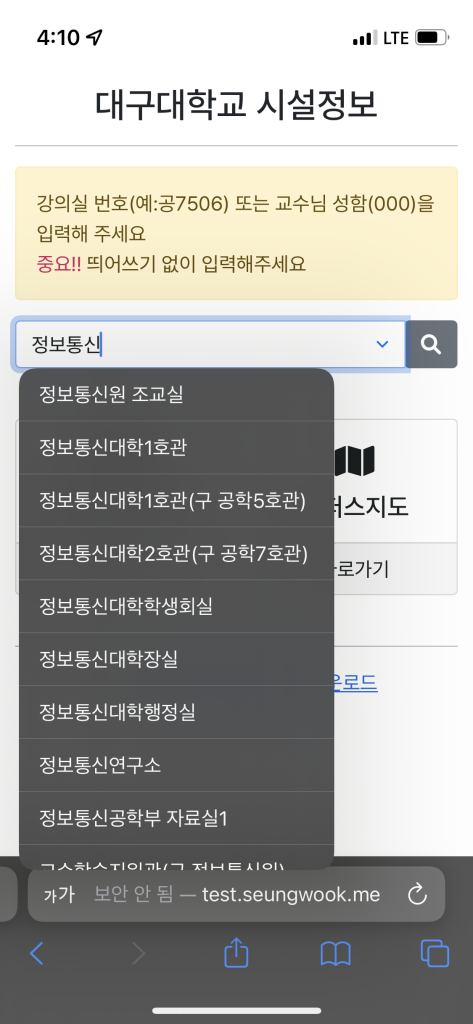
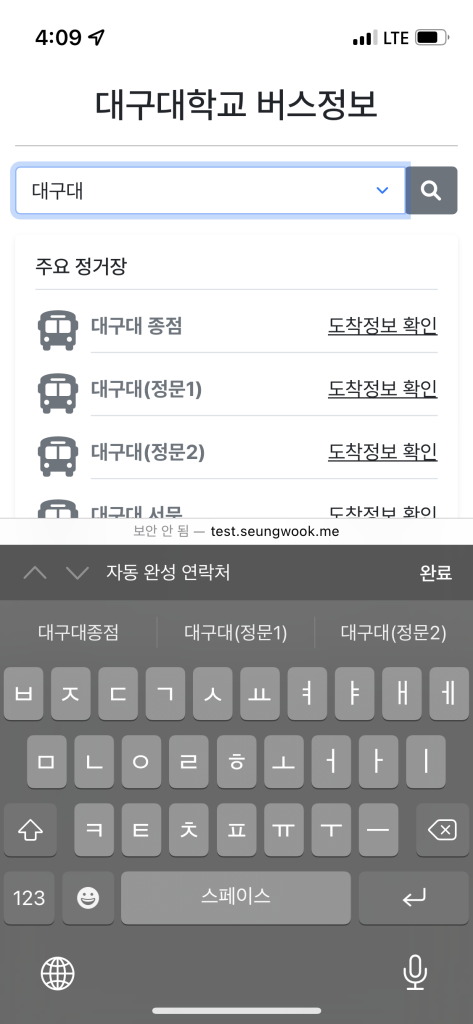
Miscthings 동아리 활동을 하면서 다양한 서비스를 만들고 배포하고 있는데요.
사용자의 편의성을 증대하기 위해 기존에 진행하고 있는 서비스를 보완하고 통합 어플을 만들고자 합니다.
기존의 제작하고 있던 밥약과 다양한 정보들을 통합하여 제공하여 재학생의 만족도를 높여가는 서비스를 완성 시키도록 하겠습니다.
This is not a spaghetti, it’s jjamppong
대구대 사이트에 있는 정보들을 하나로 통합하여 검색할 수 있으면 좋을 것 같아 개발하였습니다.
현재 대구대 사이트에는 아래와 같은 시설 검색이 가능합니다.
추가적으로 비공개 데이터도 있습니다
이러한 데이터를 검색하려면 메뉴를 누르고 링크를 타고 접속해야 검색이 가능합니다.
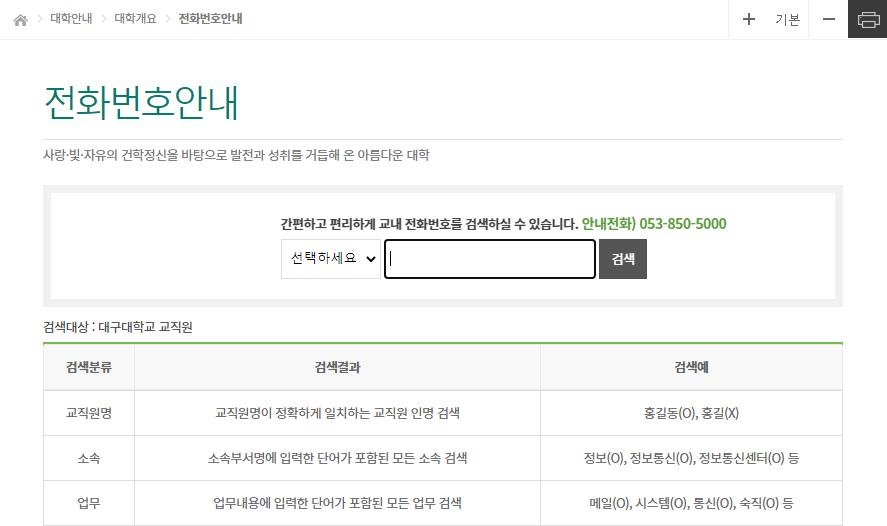
예를 들어 전화번호를 검색하려면
① 상단 메뉴에서 대학안내 → 대학개요 → 전화번호안내 링크를 통해 접속하고
② 검색 분류를 선택한 뒤
③ 전화번호를 검색 해야 합니다.
이런 파편화된 데이터를 하나의 검색 박스에서 위 나열된 것을 검색하도록 하는것이 목표입니다.
우선 현재 데이터는 전부 JSON 으로 저장되어 있습니다. 예시 JSON 은 다음과 같습니다.
# 강의실 정보
{
"id":"법행1100",
"name":"1층 공통공간",
"floor":"1층",
"type":"17558688",
"location":"법행정대학관"
}
# 시설 정보
{
"id": "중앙도서관열람관",
"sectors": "편의점",
"name": "이마트24",
"floor": "지하",
"office_phone": "",
"phone_number": "010-****-****",
"type": "10263233"
}
# 학과 정보
{
"id":"인문대학",
"name":"한국어문학부",
"url":"http://koreandu.daegu.ac.kr/",
"image_url":"http://koreandu.daegu..."
}
# 연락처 정보
{
"name_kr": "강**",
"upmu": null,
"buseo": "재활과학대학 재활건강증진학과",
"user_upmu": "교육지원조교",
"bojik_nm": " ",
"sosok": null,
"jik_id": "*****",
"user_telno": "6095",
"e_mail": "********@naver.com",
"hompy_addr": null,
}이 정보를 키워드 형태로 검색할 수 있게 가공해야 합니다.

MariaDB 같은 RDBMS에 집어넣으려면 JSON을 표 처럼 변환해줘야 합니다. 검색과 별개로 사용자에게 보여줄 정보는 필요하기 때문에 필수적인 항목만 추려 보았습니다.
이제 위 형태로 변환시키는 코드를 만듭니다. 배열로 처리 할 수 있지만 기억력도 좋지 않은데다 표를 봐 가면서 해야하기 때문에 dataclass 로 정의해보도록 하겠습니다.
from dataclasses import dataclass
from typing import Optional
@dataclass
class CsvForm:
idx: Optional[int] = None
blah_id: Optional[str] = None
name: Optional[str] = None
location: Optional[str] = None
tel_no: Optional[str] = None
mobile_no: Optional[str] = None
category: Optional[str] = None
web_address: Optional[str] = None
email_address: Optional[str] = None
tags: Optional[str] = None
def __get_data_array(self):
return [
self.idx, self.blah_id, self.name, self.location,
self.tel_no, self.mobile_no, self.category, self.web_address,
self.email_address, self.tags,
]
def __getitem__(self, item):
return self.__get_data_array()[item]
def __repr__(self):
return self.__get_data_array()
def __len__(self):
return len(self.__get_data_array())
어쨌든 CSV 로 변환해야 하기 때문에 class 형태지만 배열처럼 동작해야 합니다. __getitem__() 과 __len__() 을 구현해 줌으로써 배열 처럼 동작하게 할 수 있습니다.
(2) 에서는 sqlite3 을 사용해서 메모리에 데이터베이스를 올리고 쿼리 생성까지 만들어 보겠습니다.
함수의 매개변수에는 기본값(default value)을 선언할 수 있습니다. 만약 어떤 매개변수에 기본값을 선언했다면 호출할 때 인자를 전달하지 않아도 되며 이때 선언문에 명시한 기본값이 적용됩니다.
* 기본값 활용
fun main(){
fun some(data1: Int, data2: Int = 10): Int{
return data1 * data2
}
println(some(10))
println(some(10, 20))
}
>> 실행결과
100
200어떤 함수의 매개변수가 여러 개면 호출할 때 전달한 인자를 순서대로 할당합니다. 즉, 첫 번째 인자를 첫 번째 매개변수에 할당합니다. 그런데 호출할 때 매개변수명을 지정하면 매개변숫값의 순서를 바꿔도 됩니다.
* 매개변수명 생략 - 매개변수 순서대로 할당
fun some(data1: Int, data2: Int): Int {
return data1 * data2
}
println(some(10, 20))위 소스처럼 some() 이라는 함수에 매개변수를 2개 선언하고 some(10, 20)으로 함수를 호출하면 data1에 10, data2에 20을 대입합니다. 그런데 오른쪽처럼 매개변수명을 지정해서 호추할 수 있습니다.
* 매개변수명을 지정하여 호출 some(data2 = 20, data1 = 10)
매개변수명을 지정하여 호출하는 것을 명명된 매개변수라고 합니다. 이렇게 하면 함수 선언문의 매개변수 순서에 맞춰 호출하지 않아도 됩니다.
컬렉션 타입
여러개의 데이터를 표현하는 방법이며, Array List Set Map 이 있습니다.
Array – 배열 표현
코틀린의 배열은 Array 클래스로 표현합니다. Array 클래스의 생성자에서 첫 번째 매개변수 배열의 크기이며 두 번째 매개변수는 초깃값을 지정하는 함수 입니다. 배열의 타입은 제네릭으로 표현합니다. Array<Int>로 선언하면 정수 배열을 의미하며 Array<String>으로 선언하면 문자열 배열을 의미합니다.
* Array 클래스의 생성자 <init>(size: Int, init: (Int) -> T)
오른쪽 코드는 Array() 생성자의 첫 번째 인자가 3이고 두번 째 인자는 0을 반환하는 람다 함수이므로 0으로 초기화한 데이터를 3개 나열한 정수형 배열을 선언합니다.
* 배열 선언 예
val data1: Array<Int> = Array(3, {0})배열의 데이터에 접근할 때는 대괄호([])를 이용해도 되고 set()이나 get() 함수를 이용할 수도 있습니다.
* 배열의 데이터에 접근하는 예
fun main(){
val data1: Array<Int> = Array(3, {0})
data[0] = 10
data[1] = 20
data.set(2, 30)
println(
"""
array size : ${data1.size}
array data : ${data1[0]}, ${data1[1]}, ${data1.get(2)}
"""
)
}
>> 실행결과
array size : 3
array data : 10, 20, 30기초 타입의 배열
기초 타입이라면 Array 클래스를 사용하지 않고 각 기초 타입의 배열을 나타내는 클래스를 이용할 수도 있습니다. 즉 BooleanArray, ByteArray, CharArray, DoubleArray, FloatArray, IntArray, LongArray, ShortArray 클래스를 이용할 수도 있습니다.
* 기초 타입 배열 선언
val data1: IntArray = IntArray(3, {0})
val data2: BooleanArray = BooleanArray(3, {false})또한 arrayof() 라는 함수를 이용하면 배열을 선언할 때 값을 할당할 수도 있습니다.
* 배열 선언과 동시에 값 할당
fun main(){
val data1 = arrayOf<Int>(10, 20, 30)
println(
"""
array size : ${data1.size}
array data : ${data1[0]}, ${data1[1]}, ${data1.get(2)}
"""
)
}
>> 실행결과
array size : 3
array data : 10, 20, 30arrayOf() 함수도 기초 타입을 대상으로 하는 booleanArrayOf(), byteArrayOf(), charArrayOf(), doubleArrayOf(), floatArrayOf(), intArrayOf(), longArrayOf(), shortArrayOf() 함수를 제공합니다.
* 기초 타입 arrayOf() 함수 val data1 = intArrayOf(10, 20, 30) val data2 = booleanArrayOf(true, false, true)
List Set Map
Collection 인터페이스 타입으로 표현한 클래스이며 통틀어서 컬렉션 타입 클래스라고 합니다.
List : 순서가 있는 데이터 집합으로 데이터 중복을 허용
Set : 순서가 없으며 데이터의 중복을 허용하지 않음
Map : 키와 값으로 이루어진 데이터 집합으로 순서가 없으며 키의 중복은 허용하지 않음
Collection 타입의 클래스는 가변 클래스와 불변 클래스로 나뉩니다.
불변 클래스 : 초기에 데이터를 넣으면 이제 변경 불가
가변 클래스 : 초기에 데이터를 넣은 후에도 추가하거나 변경 가능
List를 예로 들면 코틀린에서는 가변과 불변이라는 2가지 타입의 클래스를 제공합니다. List는 불변 타입이므로 size(), get() 함수만 제공하고 데이터를 추가하거나 변경하는 add(), set() 함수는 제공하지 않습니다. 그런데 MutableList는 가변 타입이므로 size(), get() 함수 이외에 add(), set()함수를 이용할 수 있습니다. 이는 Set, Map 도 마찬가지 입니다. Set, Map 은 불변 타입이며 MutableSet, MutableMap은 가변 타입입니다.
* 가변 타입과 불변 타입성 *
<구분> <타입> <함수> <특징>
List List listOf() 불변
MutableList mutableListOf() 가변
Set Set setOf() 불변
MutableSet mutableSetOf() 가변
Map Map mapOf() 불변
MutableMap mutableMapOf() 가변다음 소스는 listOf() 함수로 List 객체를 만들며 매개변수에 초깃값을 대입합니다. List 객체의 데이터는 배열처럼 대괄호를 이용해 얻을 수도 있지만 get() 함수를 사용해도 됩니다.
* 리스트 사용 예
fun main(){
var list = listOf<Int>(10, 20, 30)
println(
"""
list size : ${list.size}
list data : ${list[0]}, ${list.get(1)}, ${list.get(2)}
"""
)
}
>> 실행결과
list size : 3
list data : 10, 20, 30MutableList는 mutableListOf() 함수로 만들며 데이터를 추가하거나 변경할 때는 add(), set() 함수를 이용할 수 있습니다.
* 가변 리스트 사용 예
fun main() {
var mutableList = mutableListOf<Int>(10, 20, 30)
mutableList.add(3, 40)
mutableList.set(0, 50)
println(
"""
list size : ${mutableList.size}
list data : ${mutableList[0]}, ${mutableList.get(1)},
${mutableList.get(2)}, ${mutableList.get(3)}
"""
)
}
>> 실행결과
list size : 4
list data : 50, 20, 30, 40Map 객체는 키와 값으로 이루어진 데이터의 집합입니다. Map 객체의 키와 값은 Pair 객체를 이용할 수도 있고 ‘키 to 값’ 형태로 이용할 수도 있습니다.
* 집합 사용 예
fun main() {
var map = mapOf<String, String>(Pair("one", "hello"), "two" to "world")
println(
"""
map size : ${map.size}
map data : ${map.get("one")}, ${map.get("two")}
"""
)
}
>> 실행결과
map size : 2
map data : hello, world위 코드에서 mapOf() 함수를 이용해 Map 객체를 만들었습니다. 이때 <String, String> 제네릭 타입을 지정하였고 따라서 Map 객체에 대입되는 데이터의 키와 값은 모두 String 타입이 됩니다. Pair(“one”, “hello”)처럼 키값을 Pair 객체로 표현해서 Map에 대입할 수도 있고, “two” to “world” 처럼 Map 객체에 대입할 수도 있습니다.
새로 배운 내용
집계나 조건 검색 할때 query 보다 필터가 더 빠름
이유는 필터는 100% 일치하는 문서만 반환하는 데 비해 쿼리는 입력값과 비슷한 문서도 검색 하고 점수계산을 시행함.
(+) 필터의 이점은 자주 사용하는 필터는 엘라스틱이 자동으로 캐시해준다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-filter-context.html
여러개의 필터(조건)를 걸려면 부울 쿼리 사용
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-bool-query.html
{
"bool" : {
"must" : [],
"should" : [],
"must_not" : [],
"filter": []
}
}부울 쿼리에서 사용되는 모드
이번주는 밥약의 프론트 디자인을 진행하였습니다.
디자이너 안 선생님이 기존 제작하신 디자인 소스코드를 참고하여 진행하였습니다. 디자이너 안 선생님께 감사인사 드립니다.
마지막 사진인 타임테이블 제작에 좀 고생 했지만, 데이터를 삽입하면 동적으로 잘 동작합니다.
1. 리스트의 최솟값을 찾는다.
2. 그 값을 리스트의 맨 앞자리 값과 교체한다.
(맨 앞자리 값이 최솟값일 경우 Pass)
3. 1,2 과정을 정렬이 완료 시점까지 반복.

#include<stdio.h>
int main()
{
int A[10], i, j, c, k;
for(i=0 ; i<10 ; i++)
{
scanf("%d",&A[i]); //숫자 10개를 입력 받는다.
}
for(i=0 ; i<9 ; i++) //맨 앞자리 숫자를 잡아준다.
{
for(j=i+1 ; j<10 ; j++)//맨 앞자리 숫자를 제외한 리스트 값을 비교한다.
{
if(A[i] > A[j]) // 최솟값이 순서대로 Swap한다.
{
c = A[i];
A[i] = A[j];
A[j] = c;
}
}
printf("정렬 %d회 : ",i+1); //정렬 과정을 출력한다.
for(k=0;k<10;k++)
printf("%d ",A[k]);
printf("\n");
}
}선택 정렬 알고리즘 핵심
for(i=0;i<9;i++)
{
for(j=i+1;j<10;j++) //j=i+1 초기 값 설정으로 정렬된 리스트에 영향 X
{
if(A[i]>A[j])//조건 식에 따라 오름차순 또는 내림차순으로 정렬 가능.
{
c=A[i]; //모든 정렬에서 핵심 부분이다.
A[i]=A[j]; //각 칸마다 있는 리스트 숫자를 서로 Swap 위해서는
A[j]=c; //변수c를 사용하여 리스트의 숫자를 보관한다.
}
}
}선택 정렬 추가 알고리즘(함수)
int SelectionSort(int SortList, int n)
{
int i, j, min = 0, sp = 0;
for (i = 0; i < n - 1; i++)
{
min = i;
for (j = i + 1; j < n; j++)
{
if (SortList[min] > SortList[j])
min = j;
}
//리스트 중 가장 작은 값과 SortList[i]값 Swap Code.
sp = SortList[i];
SortList[i] = SortList[min];
SortList[min] = sp;
}
}선택 정렬 알고리즘을 함수(SelectionSort)로 사용하는 방법도 있습니다.
활동을 하면서 글의 주제 선정과 방향성에 대해서도 아직 부족하다고 느낍니다.
프로그래밍 언어와 관련된 코딩 공부와 전공에 관한 실습에 대해서도 추가적으로 공부하여 글을 올려볼 예정입니다. 저의 글을 보시고 편하게 피드백 해주시면 감사하겠습니다.
◆ 그 외 사항
포스팅 계획 – 4월 : MVC 모델링, 정처기 실기(+중간) / 5월 : 스프링부트, MVC 모델링 / 6월 : 졸업 작품(+기말) / 7월 : 스프링부트 / 8월 ~ : 알고리즘과 CS, JPA, 스프링부트를 포함한 미정
Char, Str (문자와 문자열)
Char는 문자를 표현하는 타입입니다. 코틀린 코드에서 Char 타입의 데이터는 문자를 작은따옴표 (‘ex) Char = ‘a’ ‘) 로 감싸서 표현합니다. 단 Number 타입으로는 표현할 수 없습니다.
* 문자 표현
val a: Char = 'a'
if (a==1) { // 오류 발생
}Str는 문자열을 표현하는 타입입니다. String 타입의 데이터는 문자열을 큰 따옴표(“ex) “a” “)나 삼중 따옴표 (“””) 로 감싸서 표현합니다. 큰따옴표로 표현한 문자열에서 Enter나 Tab에 의한 줄 바꿈이나 들여쓰기 등을 그대로 유지하려면 역슬래시로 시작하는 이스케이프 시퀀스를 입력해야 합니다. 그러나 삼중 따옴표로 표현할 때는 키보드로 입력한 줄 바꿈이나 들여쓰기 등이 데이터에 그대로 반영됩니다. 다음 코드와 실행 결과를 참고해보면 됩니다.
* 문자열 표현
fun main(){
val str1 = "Hi \n Hi"
val str2 = """
Hi
Hi
"""
println("str1 : $str1")
println("str2 : $str2")
}
---------------------------------[실행결과]
str1 : Hi (\n 반영됨 줄바꿈)
Hi
Str2 : (""" 키보드로 입력한 줄내용 반영)
Hi
Hi안드로이드 스튜디오에서 삼중 따옴표를 사용하면 닫는 따옴표 뒤에 .trimIndent() 함수가 자동으로 추가됩니다. 이 함수는 문자열 앞에 공백을 없애 줍니다.
Str 타입의 데이터에 변숫값이나 어떤 연산식의 결괏값을 포함해야 할 때는 $ 기호를 이용합니다. 이를 문자열 템플릿 이라고 합니다.
* 문자열 템플릿
fun main(){
fun sum(no: Int):Int{
var sum = 0
for (i in 1..no){
sum += i
}
return sum
}
val name: String = "KDIDI"
println("name : $name, sum : ${sum(10)}, plus : ${10+20}")
-----------------------------------------------------------[실행결과]
name : KDIDI, sum : 55(1부터 10까지의 sum+=i에 넣은 값), plus : 30($10+20 결과)Any – 모든 타입
Any는 코틀린에서 최상위 클래스입니다. 모든 코틀린의 클래스는 Any의 하위 클래스 입니다. 따라서 Any 타입으로 선언한 변수에는 모든 타입의 데이터를 할당할 수 있습니다.
(최상위 클래스)
모든 타입의 데이터를 할당할 수 있음
Any 타입 사용 예 val data1: Any = 10 -> int형 val data2: Any = "Hi" -> Str형 class User val data3: Any = User() -> Class형
Unit – 반환문 없는 함수
Unit은 다른 타입과 다르게 데이터의 형식이 아닌 특수한 상황을 표현하려는 목적으로 사용합니다.
Unit 타입으로 선언한 변수에는 Unit 객체만 대입할 수 있습니다. 따라서 Unit 타입으로 변수를 선언할 수는 있지만 의미가 없습니다. 이런 Unit 타입은 주로 함수의 변환 타입으로 사용합니다. 함수에서 반환문이 없음을 명시적으로 나타날 때 Unit 타입을 사용합니다.
* Unit 타입 사용 val data1: Unit = Unit
* Unit 타입 사용 (반환문이 없는 함수)
fun some() : Unit{
println(10+20)
}함수를 선언할 때 반환 타입을 생략하면 자동으로 Unit이 적용됩니다. 즉, 오른쪽 소스는 위의 소스와 같습니다.
* 반환 타입을 생략한 예
fun some(){
println(10+20)
}
--자동으로 Unit 적용됨--Nothing – null이나 예외를 반환하는 함수
Nothing도 Unit과 마찬가지로 의미 있는 데이터가 아니라 특수한 상황을 표현합니다. Nothing 으로 선언한 변수에는 null만 대입할 수 있습니다. 즉, Nothing 으로 선언한 변수는 데이터로서는 의미가 없습니다.
* Nothing 사용 val data1: Nothing? = null
Nothing은 주로 함수의 반환 타입에 사용합니다. 어떤 함수의 반환 타입이 Nothing이면 반환은 하지만 의미 있는 값은 아니라는 의미 입니다. 항상 null만 반환하는 함수라든가 예외를 던지는 함수의 반환 타입을 Nothing 으로 선언합니다. (의미있는 값은 아니다.)
null 반환 함수와 예외를 던지는 함수
fun some1(): Nothing?{
return null
}
fun some2(): Nothing{
throw Exception()
}널 허용과 불허용
코틀린의 모든 타입은 객체이므로 변수에 null을 대입할 수 있습니다. null은 값이 할당되지 않은 상황을 의미합니다. 코틀린에서는 변수를 선언할 때 null을 대입할 수 있는 변수인지, null을 대입할 수 없는 변수인지 명확하게 구분해서 선언해야 합니다.
(null 허용 nullable) (null 불허용 not null)
이러한 구분은 변수를 선언할 때 타입 뒤에 물음표(?)로 표시합니다. 타입 뒤에 물음표를 추가 하면 널 허용으로 선언하지만 반대로 물음표를 추가하지 않으면 불허용으로 선언합니다.
널 허용과 불허용 val data1: Int = 10 data1 = null // 오류! val data2: Int? = 10 data2 = null // 성공! ----------------------- ? 유무는 있을때는 널 허용으로 선언 없을때는 널 불허용으로 선언 따라서 data1은 오류를 출력하게 되고 data2는 null을 대입하여도 정상적으로 출력하게 된다.
함수 선언하기
코틀린에서 함수를 선언하는 방법은 fun 이라는 키워드를 이용합니다.
* 함수 선언 방식
fun 함수명(매개변수명: 타입): 반환 타입 {...}함수에는 반환 타입을 선언할 수 있으며 생략하면 자동으로 Unit 타입이 적용됩니다.
* 반환 타입이 있는 함수 선언
fun some(data1: Int): Int {
return data1 * 10
}함수의 매개변수에는 var나 val 키워드를 사용할 수 없습니다. val이 자동으로 적용되며 함수 안에서 매개변숫값을 변경할 수 없습니다.
* 매개변숫값 변경 오류
fun some(data1: Int){
data1 = 20 // 오류
}